
在之前的篇章講過用 Apriori Algorithm 去 generate frequent itemsets,從而找出商品的相關法則 (Association Rules)。現在就試試用Python 去做,幸運地 python 有人寫了 Mlxtend 這個 machine learning extensions,可以直接使用 apriori function 去做。
Mlxtend 文件:
http://rasbt.github.io/mlxtend/
重溫 support 概念
要搵出 frequent itemsets,需要滿足預設的支持度 Support threshold。假如預設的 support threshold 是 0.5(50%),表示該 frequent itemset 在整個database transactions出現的次數最少達一半。
Step 1: 準備 transaction data
假設我們現在有5筆超市購物交易:
- Milk, Onion, Nutmeg, Kidney Beans, Eggs, Yogurt
- Dill, Onion, Nutmeg, Kidney Beans, Eggs, Yogurt
- Milk, Apple, Kidney Beans, Eggs
- Milk, Unicorn, Corn, Kidney Beans, Yogurt
- Corn, Onion, Onion, Kidney Beans, Ice cream, Eggs

Step 2: 用 Transaction Encoder 轉做 Array 格式
由於 apriori function 要求 data 使用 pandas DataFrame格式,如果 raw data 是其他格式,則需要用 Transaction Encoder 的 fit 和 transform 轉檔。Transaction Encoder 可以從dataset中 learns unique items,並將每一個 transaction ( Python 的 List ) 轉變成one-hot encoded boolean Numpy array。
from mlxtend.preprocessing import TransactionEncoder
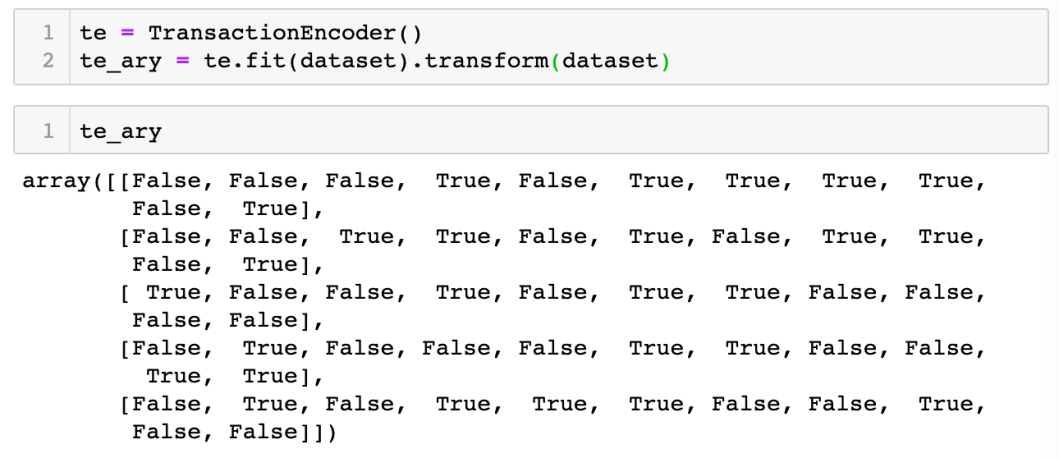
上圖可見,transform 完的 dataset 變成 NumPy array 格式,只有 True 和 False (boolean) ,這對處理大型datasets 時更有效率。
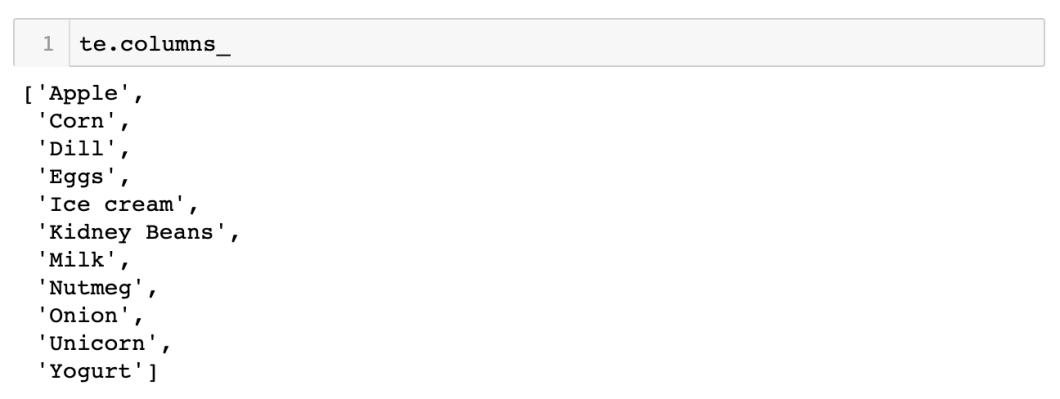
如果想 access 返 dataset 的對應 column name,就可用 columns_ attribute:
但為方便閱讀,我們可以將 array 轉成 pandas DataFrame:
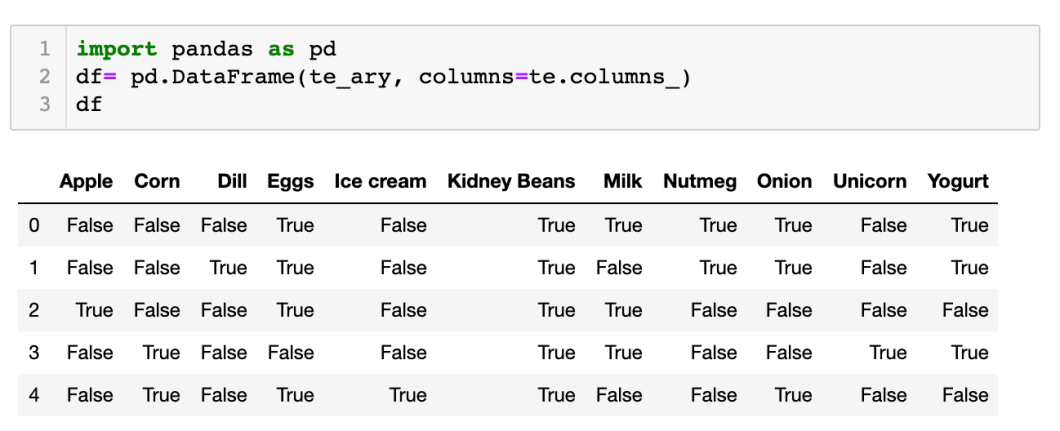
上圖表格可見,True 和 False 用來代表是否包含 column 名字。
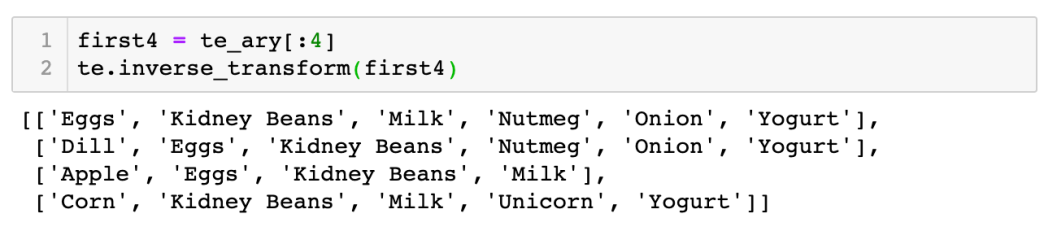
還原:假如我們想將 one-hot encoded array 還原為 transaction list,則可以用 inverse_Transform function:
step 3: 用 Apriori 找出 frequent itemsets
既然已 fit 好 dataset,現在就可以用 Apriori Algorithm 去找出 frequent itemsets。將最低支持度 (min support) 定為 60%,即在所有交易中,該產品最少佔 60%,才可符合 frequent itemset 的要求。
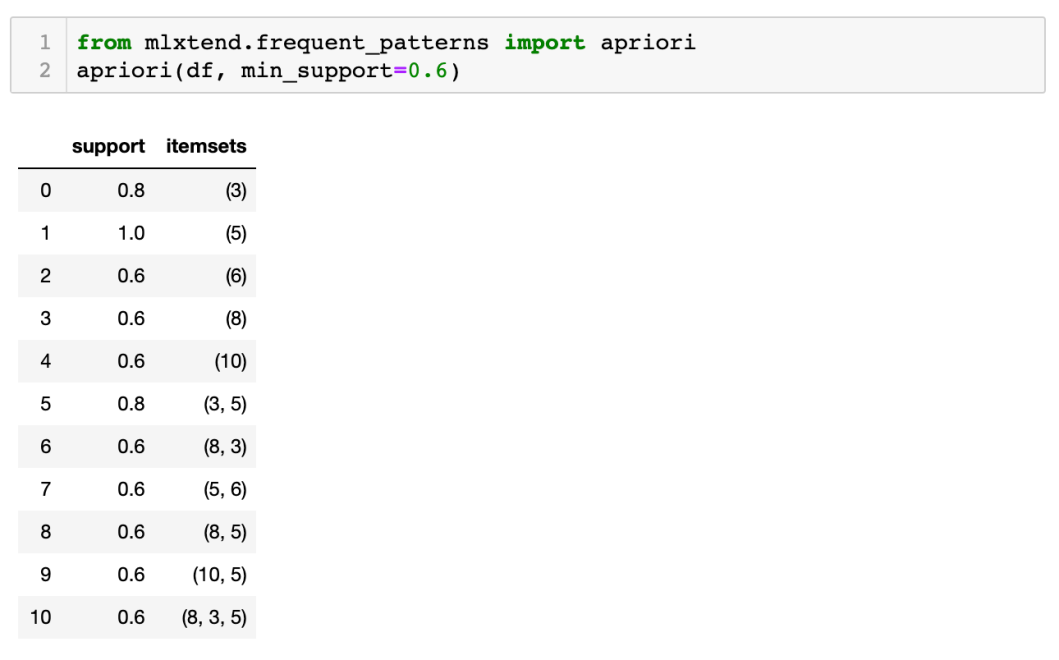
不過,因apriori 回傳的 itemsets 是 column indices,為方便閱讀,可用 use_colnames=True 來將這些 indices convert 做相應的 item names:
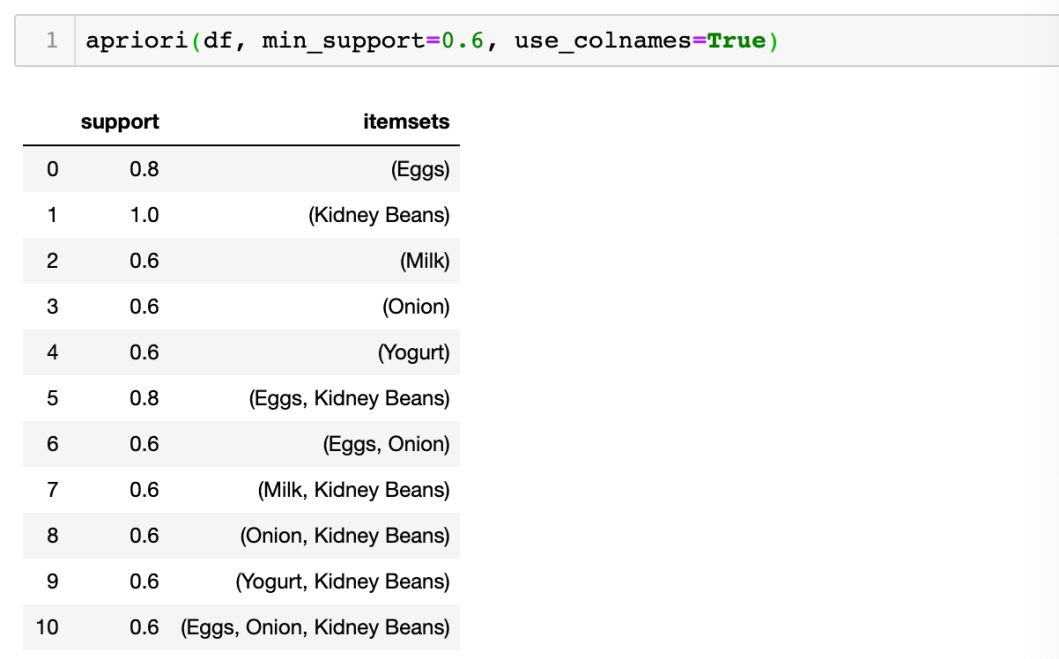
上圖顯示的 itemsets,全部都符合min support ( >0.6) 的要求,是 frequent itemsets。
Step 4:篩選結果
用 pandas 的 DataFrames 的好處是方便去 filter 結果。例如,我們只想知道包含兩件貨品的結果,而其支持度最少要有 80%。首先,我們如常用 apriori 方法找出 frequent itemsets(step 1-3),然後加入新column去儲存每個 itemset 的貨品 length。
Assign 新 column 叫 length,將 frequent_itemsets 內的 itemsets 行,apply lambda function 這個可以即時使用的 function,不像def。
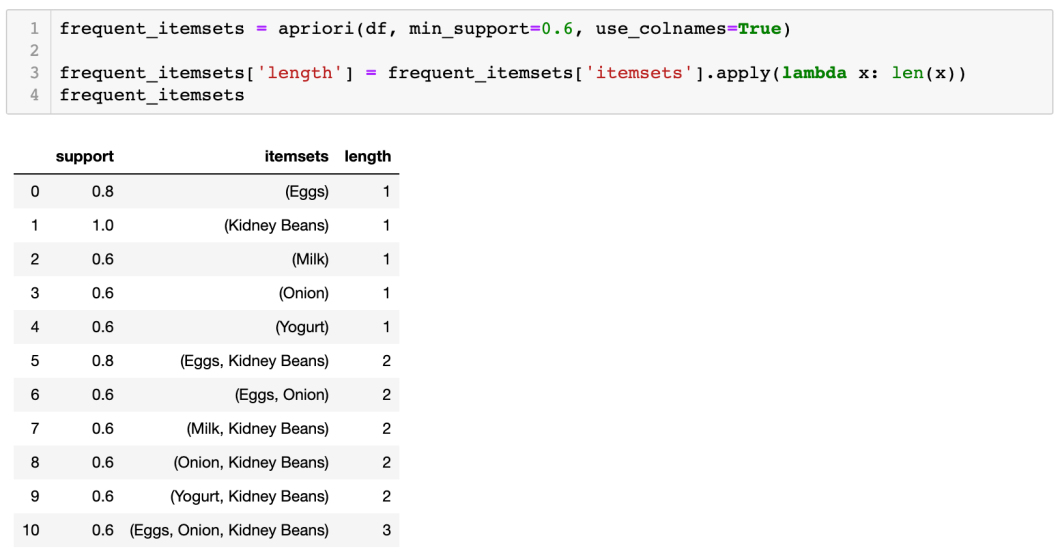
得知所有 itemsets 的 length 後,就可加入篩選條件顯示結果:
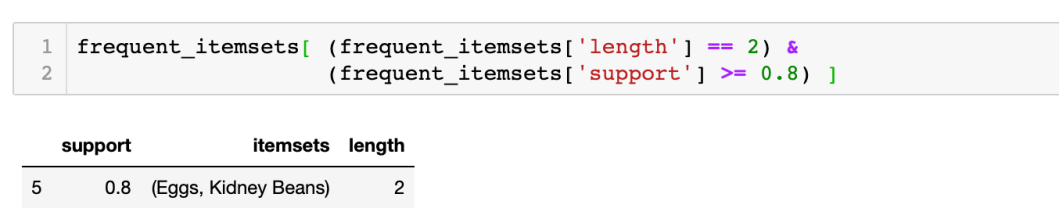
其實使用 Pandas API,可以用 itemsets 的column names 去選:

注意:itemsets 的 column 是 frozenset 的一種, 即類似 set ,但資料不能改變。
Step 5:從 frequent itemsets 中 generate association rules
自找到 frequent itemsets後,可繼續用 association_rules () 的 API ,指明自己使用的 metric 如 confidence, lift 以及相關 threshold。
API
association_rules(df, metric=’confidence’, min_threshold=0.8, support_only=False)
Generates a DataFrame of association rules including the metrics ‘score’, ‘confidence’, and ‘lift’
Parameters
df: pandas DataFrame
pandas DataFrame of frequent itemsets with columns [‘support’, ‘itemsets’]metric: string (default: ‘confidence’)
Metric to evaluate if a rule is of interest. Automatically set to ‘support’ ifsupport_only=True. Otherwise, supported metrics are ‘support’, ‘confidence’, ‘lift’, ‘leverage’, and ‘conviction’ .min_threshold: float (default: 0.8)
Minimal threshold for the evaluation metric, via themetricparameter, to decide whether a candidate rule is of interest.support_only: bool (default: False)
Only computes the rule support and fills the other metric columns with NaNs. This is useful if:a) the input DataFrame is incomplete, e.g., does not contain support values for all rule antecedents and consequentsb) you simply want to speed up the computation because you don’t need the other metrics.Returns
pandas DataFrame with columns “antecedents” and “consequents” that store itemsets, plus the scoring metric columns: “antecedent support”, “consequent support”, “support”, “confidence”, “lift”, “leverage”, “conviction” of all rules for which metric(rule) >= min_threshold. Each entry in the “antecedents” and “consequents” columns are of type
frozenset, which is a Python built-in type that behaves similarly to sets except that it is immutable (For more info, see https://docs.python.org/3.6/library/stdtypes.html#frozenset).
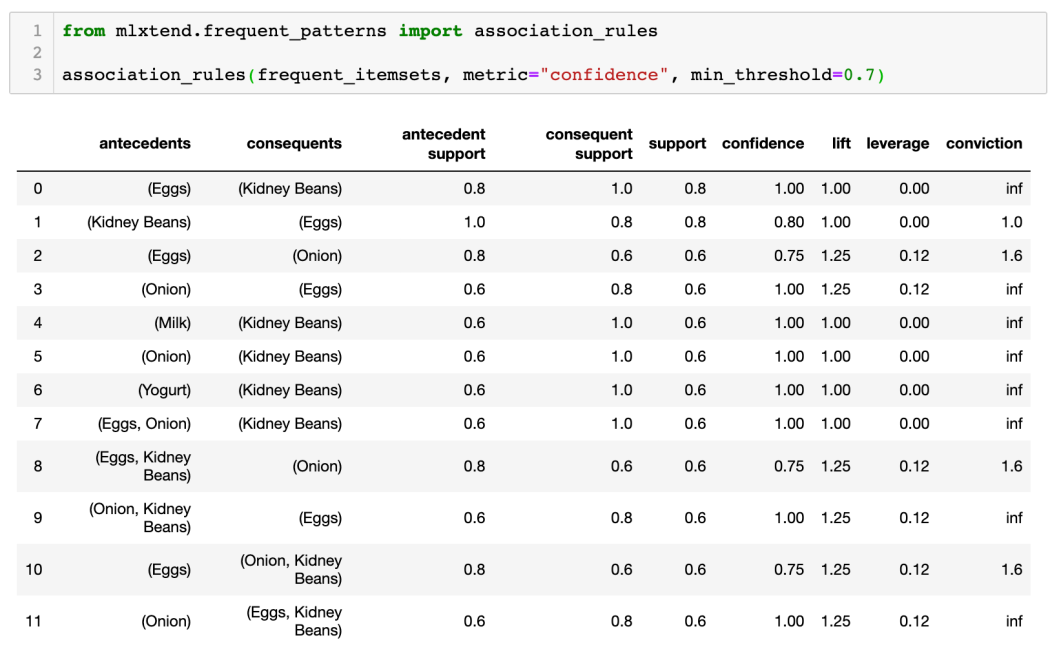
假設你只想知道擁有 confidence threshold 90% 以上的 frequent itemsets ,min threshold = 0.7。那我們就要 import association rules來進行:
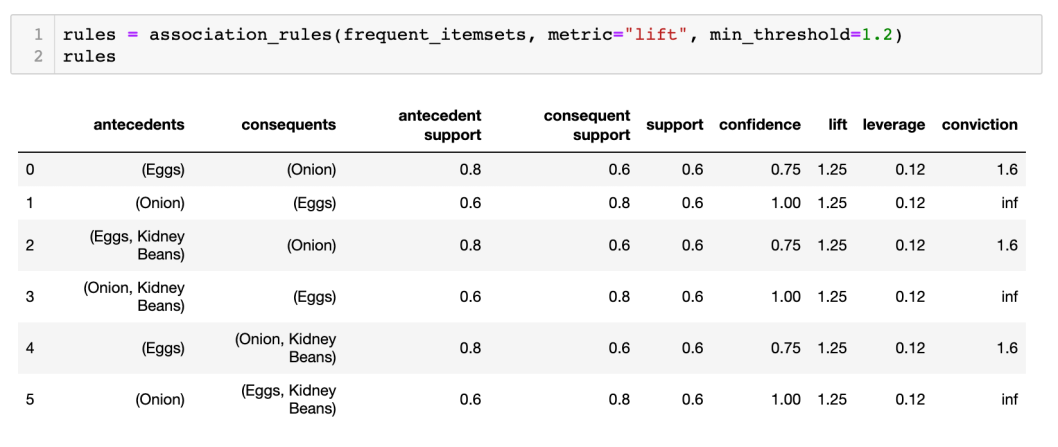
如要找出 lift > 1.2 的 rules,只需在 metric 註明是 = “lift” ,及在 min_threshold 註明 =1.2 便可:
Step 6: filter 更多 criteria,找出更精準的 association rules
如果想加入更多criteria,找出更精準的association rules,做法不難,因 Pandas 的 DataFrames 善於做 filtering。
假設我們現在設定的 criteria 是:
- 最少 2個 antecedents
- confidence > 0.75
- lift score > 1.2
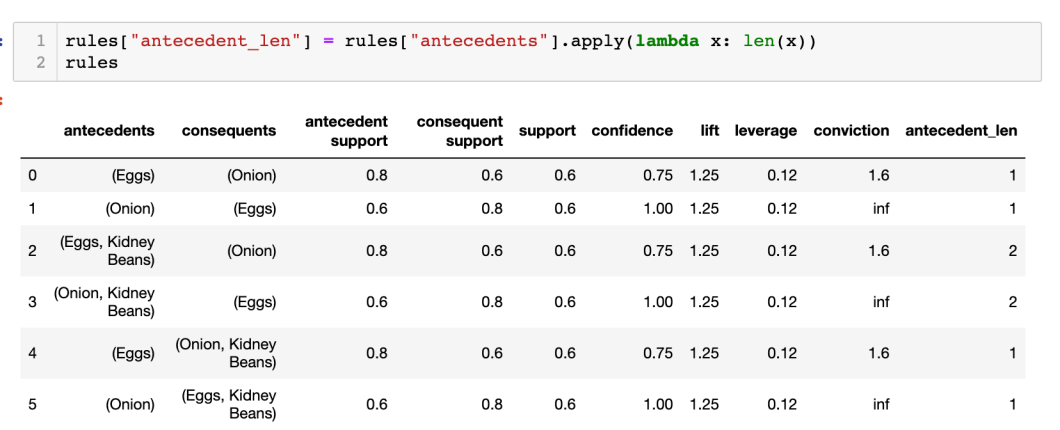
首先要在表中,加一個 column 名叫 “antecedent_len” 來顯示 antecedent 的長度:
建立這個表後,就可在表中指明想 filter 的 antecedent 長度 >=2,以及 confidence 和 lift 的要求:

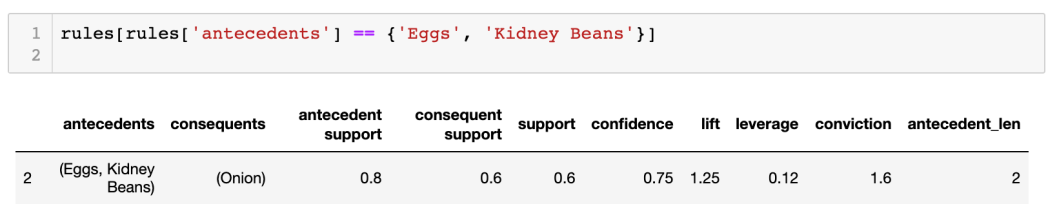
有時超市想要促銷指定貨品,來作綑綁式銷售,因此需要指明 antecedents 是什麼:
想知道Metrics 的定義,可參考:http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/
由於 itemsets column 屬於 frozenset 的其中一種,是 Python built-in type,跟 set 類似,但不能改變,好處是在執行 query 時更有效率。由於 frozenset 都是 sets,因此query時的 item order (先後次序)沒有關係。
即 query:
rules[rules['antecedents'] == {'Eggs', 'Kidney Beans'}]
rules[rules['antecedents'] == {'Kidney Beans', 'Eggs'}]rules[rules['antecedents'] == frozenset(('Eggs', 'Kidney Beans'))]rules[rules['antecedents'] == frozenset(('Kidney Beans', 'Eggs'))]
文章參考:http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/
Summary
用 Apriori 搵 association rules 的流程:
1. 轉做 one-hot encoded boolean Numpy array
2. 轉做 pandas Dataframe 表格格式
3. 用 mlxtend.frequent_patterns import apriori(+ min_sup)
4. 加回 column names
5. Filtering result
6. Generate association rules (+ min_cof)
7. Filtering result
需要使用的 libraries / api:
1. !pip3 install mlxtend
2. from mlxtend.preprocessing import TransactionEncoder
3. from mlxtend.frequent_patterns import apriori
4. from mlxtend.frequent_patterns import association_rules
5. import pandas as pd
6. frequent_itemsets[‘itemsets’].apply(lambda x: len(x))
