上一篇用了5筆超市交易做示範,今篇則用真實的超市例子去試找Frequent itemsets 和 Association Rules。這是一間 UK-based 的 online retail store 於 2010-2011年間的 所有transaction data,這間網店主要銷售節日禮品,客戶主要是批發商。
Dataset:
http://archive.ics.uci.edu/ml/machine-learning-databases/00352/
在 Dataset 中的資料包括:
- InvoiceNo.
Nominal,每宗交易的貨單號碼,6位整數,如c 字頭則表示取消。 - StockCode
Nominal,product code,5位整數 - Description
Nominal,product name - Quantity
Numeric,貨品交易數量 - InvoiceDate
Numeric,每宗交易generate 出來的日期和時間 - UnitPrice
Numeric,Product price per unit - CustomerID
Nominal,顧客編號,5位整數 - Country
Nominal,顧客所屬的國家
Step 1: 輸入 numpy, pandas libraries 及 apriori, association
在Python 做 apriori 時,需要 install mlxtend (machine-learning extension) 。由於我使用 python 3 及 Jupyter ,如果就咁用 pip3 install <module> 就會出現 Error ,好彩 stack overflow 有高人指點,原來在 Jupyter 用 Linux command 時,需要在 pip3 前加一個感歎號 ! 呢。
安裝好 mlxtend 後,就可輸入 apriori 和 association rules 兩個 functions。

Step 2: Load data
在網上 download 了 dataset 後,便放在電腦的 folder 中,並設定為 working location 。

開始 load data。由於 raw data 是 Excel format,因此需要使用 Pandas 的 read_excel 來輸入檔案: (假如是 csv,則改為 read_csv)
df = pd.read_excel ( ” filename.xlsx”)
由於已設定了 working location,因此只需要給 filename 就可。我把 dataset 儲存在 retail 變數內。

如沒有設定 working location,便需要指明 path:df = pd.read_excel ( r ” /users/ Desktop / filename.xlsx”)
如何找到檔案的 Path?
在 Mac 機要找到 Folder 或 file 的 Path 比 Windows 機麻煩,但可用 Finder 的 Go to Folder 功能。只要開啓 Finder,然後按下 toolbar 上的 Go,就可以找到 Go to Folder。只要drag 一個 file 去dialog box,就會即時顯示該File 的 path。
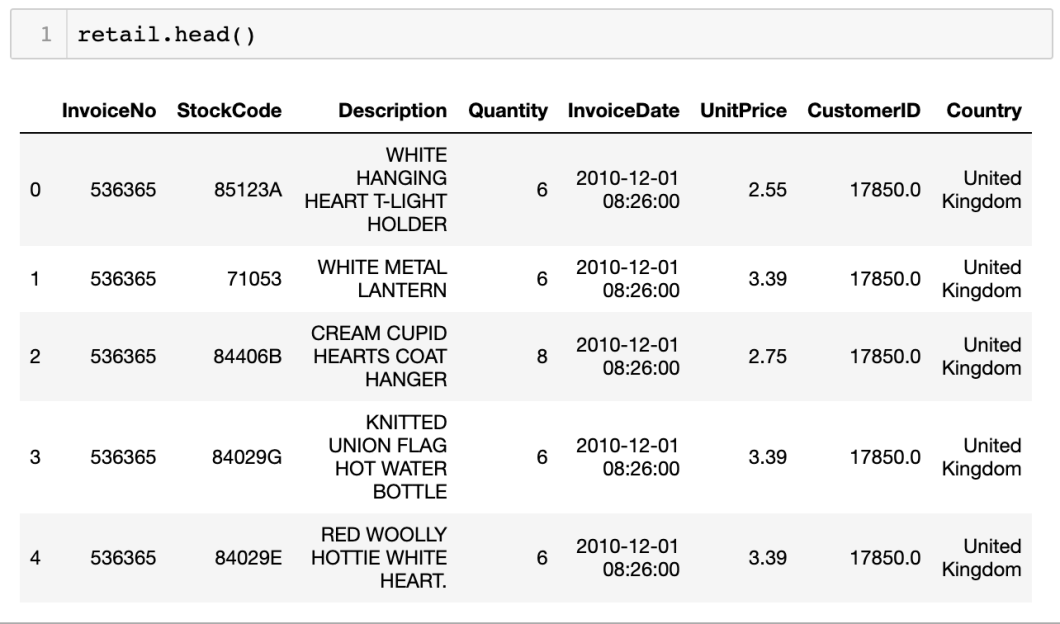
使用 head() 方法,可查閱 dataset 的首 5行資料:
也可查閱 dataset 的 columns:

也可查閱 dataset 的數據量:(no. of rows, no. of columns)

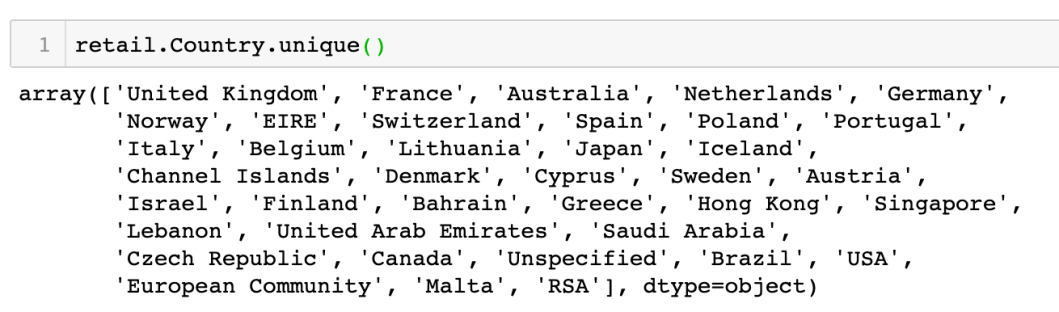
也可查閱 transaction 的國家,為了顯示不重複的結果,因此要用到 unique ():
Step 3. Cleaning data
在 dataset 中,有部份資料不全 ( missing data ) ,或有問題的 ( 過多space位),這些被視為 corrupt 或 inaccurate 的 data,都需要清理。
- 清理 description 內多餘的 space位 (只限字串前或後的extra space,並非指字與字之間的space位),可用 str.strip ()
將已清理後的內容,重新儲存在 “Description” column 內:

- 放棄缺少 invoice number 的 transactions (rows)

Pandas 的 DataFrame 有一個 method 可以remove missing values:dropna
DataFrame.dropna(self, axis=0, how=’any’, thresh=None, subset=None, inplace=Falseaxis = 0 或 index:即係指 Drop rows which contain missing values
如果 axis = 1 或 columns:即表示 Drop columns which contain missing valuehow = any :即係If any NA values are present, drop that row or column
how = all:If all values are NA, drop that row or column.thresh = 數字 (optional) :想 keep 幾多 non-NA values, 例: thresh = 2 表示只保留最少有2個non-values 的 rows
subset 是如果 drop rows, Labels along other axis to consider, these would be a list of columns to include.
inplace: If True, do operation inplace and return None. 表示只會保留含 valid entries 的 rows
- 放棄在 invoice number 前有C 字的 transactions (rows)

Step 4. 將data 以交易地區劃分

Step 5. 將 data 轉做 hot encoding
寫 hot encode function,令 data 能符合library 的要求:

將每個地區的data encode:

Step 6: 為每個地區 build model 及 形成 association rules
法國:
使用 apriori algorithm 設定 minium support,找出 frequent items:

再設定 association rules:
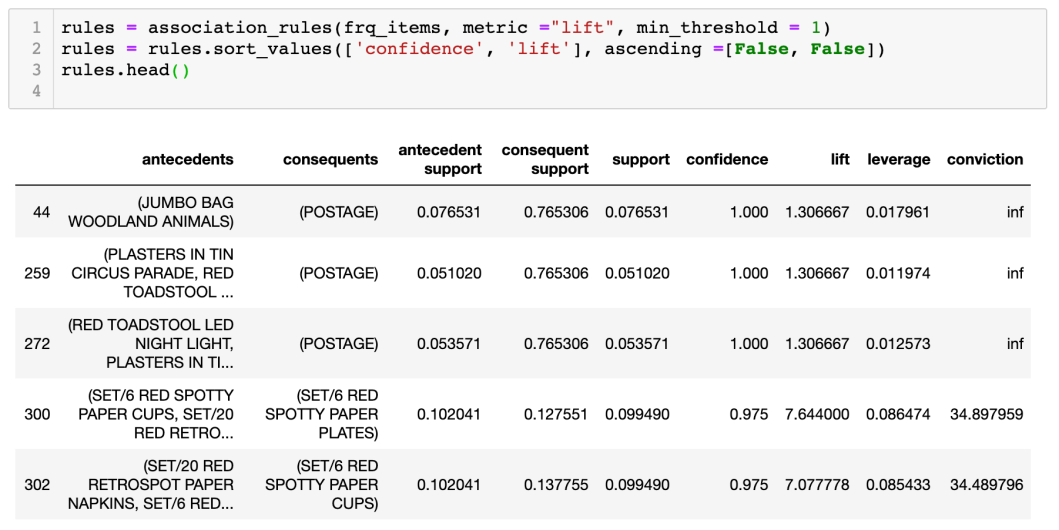
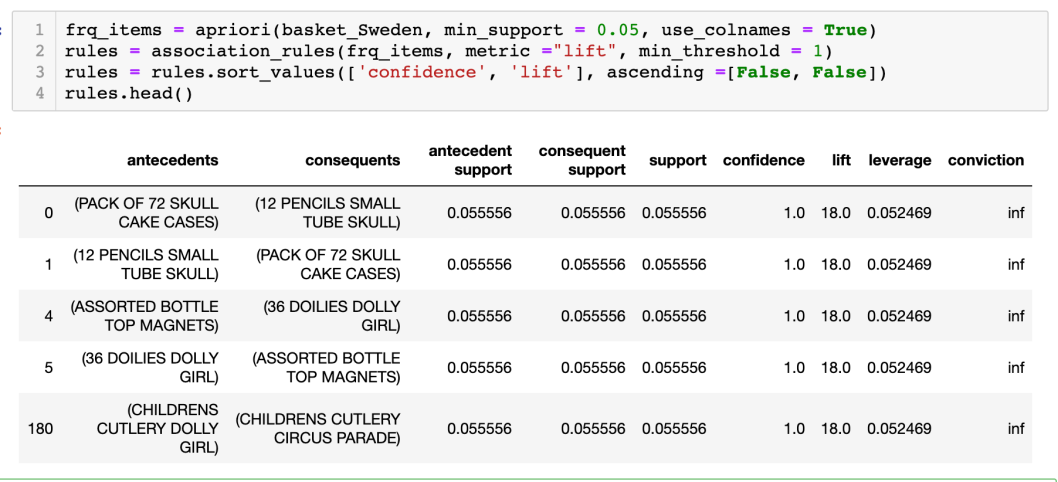
從上表可見,紙杯和紙碟會一起購買,這是由於法國的文化是每星期都會有朋友和家人聚會,但法國已禁止使用膠物品,所以法國人需要買紙製品去取代。
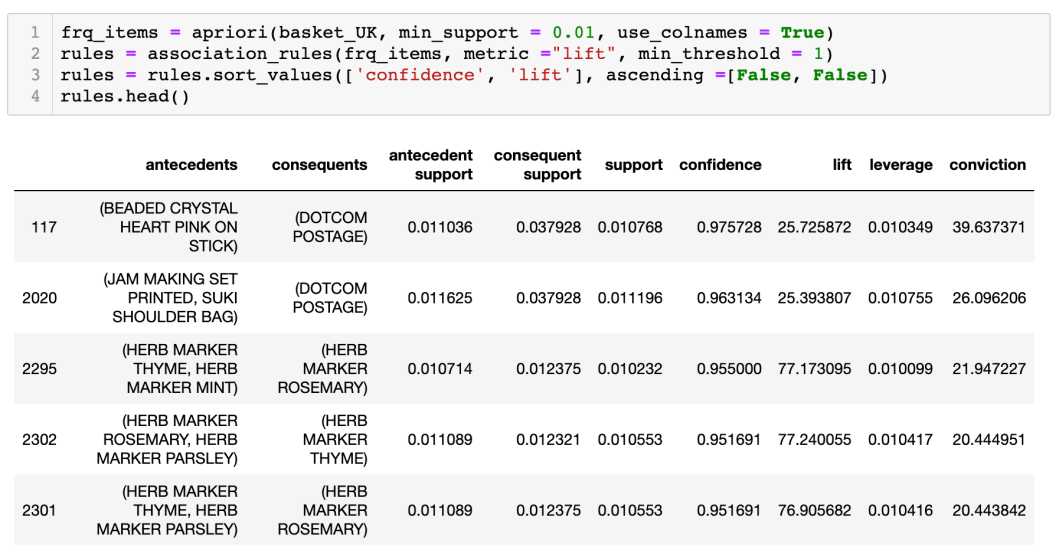
英國
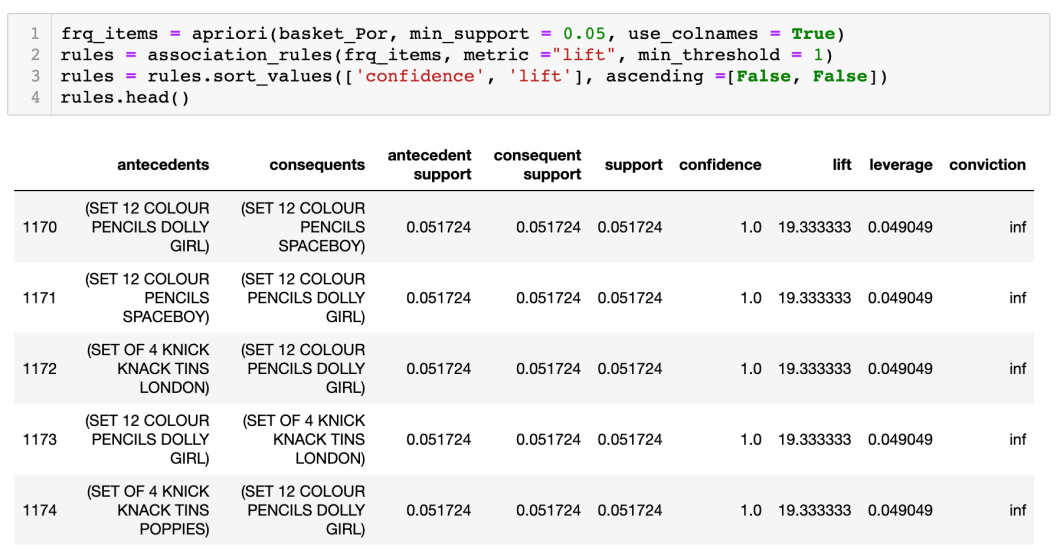
葡萄牙
瑞典